一、知识背景
1.读取excel的方法选择问题
java中读excel中的时间,我们通常用POI去解析,在使用new HSSFWorkbook(NEW FileInputStream(excelFile))来读取Workbook,对Excel2003以前(包括2003)的版本没有问题,但读取Excel2007时发生如下异常:
org.apache.poi.poifs.filesystem.OfficeXmlFileException: The supplied DATA appears TO be IN the Office 2007+ XML. You are calling the part of POI that deals WITH OLE2 Office Documents. You need TO CALL a different part of POI TO PROCESS this DATA (eg XSSF instead of HSSF) 该错误意思是说,文件中的数据是用Office2007+XML保存的,而现在却调用OLE2 Office文档处理,应该使用POI不同的部分来处理这些数据,比如使用XSSF来代替HSSF。 于是按提示使用XSSF代替HSSF,用new XSSFWorkbook(excelFile)来读取Workbook,对Excel2007没有问题了,可是在读取Excel2003以前(包括2003)的版本时却发生了如下新异常:org.apache.poi.openxml4j.exceptions.InvalidOperationException: Can't open the specified file: '*.xls' 该错误是说,操作无效,不能打开指定的xls文件。 下载POI的源码后进行单步调试,发现刚开始的时候还是对的,但到ZipFile类后就找不到文件了,到网上查了下,原来是XSSF不能读取Excel2003以前(包括2003)的版本,这样的话,就需要在读取前判断文件是2003前的版本还是2007的版本,然后对应调用HSSF或XSSF来读取。 简而言之:由于HSSFWorkbook只能操作excel2003一下版本,XSSFWorkbook只能操作excel2007以上版本,所以利用Workbook接口创建对应的对象操作excel来处理兼容性2.读取excel包含多sheet多数据的时候,出现内存溢出的问题。
POI提供UserModel和事件驱动两种方式读取excel。UserModel方式操作简洁,但是内存消耗大,稍微大一点的excel读取就会报内存溢出
二、解析步骤
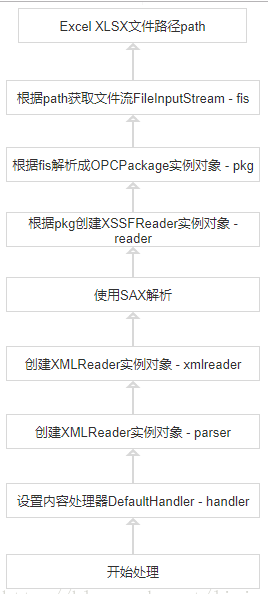
当使用POI事件模式解析Excel XLSX文档时:
- POI根据xlsx文档的路径path获取到文件File - file
- 使用java.util.zip.ZipFile打开file文件 - zip
- 从zip中获取到[Content_Types].xml
- 解析[Content_Types].xml,记录解析出Excel各个xml名称:ArrayList
- Excel解析成ZipPackage实例对象
三、代码样例
1、从DefaultHandler派生事件处理类ExcelAbstract
import java.io.InputStream;import java.sql.SQLException;import java.util.HashMap;import java.util.Map;import org.apache.poi.xssf.eventusermodel.XSSFReader;import org.apache.poi.xssf.model.SharedStringsTable;import org.apache.poi.xssf.usermodel.XSSFRichTextString;import org.apache.poi.openxml4j.opc.OPCPackage;import org.xml.sax.Attributes;import org.xml.sax.InputSource;import org.xml.sax.SAXException;import org.xml.sax.XMLReader;import org.xml.sax.helpers.DefaultHandler;import org.xml.sax.helpers.XMLReaderFactory;/** * POI事件驱动读取Excel文件的抽象类。 * * @author Charles * */public abstract class ExcelAbstract extends DefaultHandler { private SharedStringsTable sst; private String lastContents; private boolean nextIsString; private String curCellName= ""; private int curRow = 0; private boolean numberFlag; private boolean isTElement; /** * 读取当前行的数据。key是单元格名称如A1,value是单元格中的值。如果单元格式空,则没有数据。 */ private Map rowValueMap = new HashMap<>(); /** * 处理单行数据的回调方法。 * * @param curRow 当前行号 * @param rowValueMap 当前行的值 * @throws SQLException */ public abstract void optRows(int curRow, Map rowValueMap); /** * 读取Excel指定sheet页的数据。 * * @param filePath 文件路径 * @param sheetNum sheet页编号.从1开始。 * @throws Exception */ public void readOneSheet(String filePath, int sheetNum) throws Exception { OPCPackage pkg = OPCPackage.open(filePath); XSSFReader r = new XSSFReader(pkg); SharedStringsTable sst = r.getSharedStringsTable(); XMLReader parser = getSheetParser(sst); // 根据 rId# 或 rSheet# 查找sheet InputStream sheet2 = r.getSheet("rId" + sheetNum); InputSource sheetSource = new InputSource(sheet2); parser.parse(sheetSource); sheet2.close(); pkg.close(); } public void readAllSheet(String filePath) throws Exception { OPCPackage pkg = OPCPackage.open(filePath); XSSFReader r = new XSSFReader(pkg); SharedStringsTable sst = r.getSharedStringsTable(); XMLReader parser = getSheetParser(sst); SheetIterator sheets = (SheetIterator) r.getSheetsData(); while(sheets.hasNext){ InputStream sheet = sheets.next(); InputSource sheetSource = new InputSource(sheet2); parser.parse(sheetSource); sheet2.close(); } pkg.close(); } @Override public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException { // c => 单元格 if (name.equals("c")) { // 如果下一个元素是 SST 的索引,则将nextIsString标记为true String cellType = attributes.getValue("t"); if (cellType != null && cellType.equals("s")) { nextIsString = true; } else { nextIsString = false; } String cellNumberType = attributes.getValue("s"); if (cellNumberType .equals("2")) { numberFlag= true; } else { numberFlag= false; } } if (name.equals("t")) { isTElement= true; } else { isTElement= false; } // 置空 lastContents = ""; /** * 记录当前读取单元格的名称 */ String cellName = attributes.getValue("r"); if (cellName != null && !cellName.isEmpty()) { curCellName = cellName; } } @Override public void endElement(String uri, String localName, String name) throws SAXException { // 根据SST的索引值的到单元格的真正要存储的字符串 // 这时characters()方法可能会被调用多次 if (nextIsString) { int idx = Integer.parseInt(lastContents); lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString(); } if(isTElement){ String value = lastContents.trim(); rowValueMap.put(curCellName,value); isTElement = false; } // v => 单元格的值,如果单元格是字符串则v标签的值为该字符串在SST中的索引 // 将单元格内容加入rowlist中,在这之前先去掉字符串前后的空白符 else if (name.equals("v")) { String value = lastContents.trim(); value = value.equals("") ? " " : value; if(numberFlag){ BigDecimal bd = new BigDecimal(value); value = bd.setScale(3,BigDecimal.ROUND_UP).toString(); } rowValueMap.put(curCellName, value); } else { // 如果标签名称为 row ,这说明已到行尾,调用 optRows() 方法 if (name.equals("row")) { optRows(curRow, rowValueMap); rowValueMap.clear(); curRow++; } } } public void characters(char[] ch, int start, int length) throws SAXException { // 得到单元格内容的值 lastContents += new String(ch, start, length); } /** * 获取单个sheet页的xml解析器。 * @param sst * @return * @throws SAXException */ private XMLReader getSheetParser(SharedStringsTable sst) throws SAXException { XMLReader parser = XMLReaderFactory.createXMLReader("com.sun.org.apache.xerces.internal.parsers.SAXParser"); this.sst = sst; parser.setContentHandler(this); return parser; }}
2、从ExcelAbstract派生ExcelReaderUtil处理每一行数据
import java.text.SimpleDateFormat;import java.util.ArrayList;import java.util.Date;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.regex.Matcher;import java.util.regex.Pattern;import org.apache.poi.hssf.usermodel.HSSFDateUtil;/** * Excel读取公共类。 * @author Charles * */public class ExcelReaderUtil extends ExcelAbstract { /** * 提取列名称的正则表达式 */ private static final String DISTILL_COLUMN_REG = "^([A-Z]{1,})"; /** * 读取excel的每一行记录。map的key是列号(A、B、C...), value是单元格的值。如果单元格是空,则没有值。 */ private List